Recently I ran into a compute workload that I thought could benefit from concurrent programming, so I thought I'd look into what some of my options were, as a .NET developer. Before I get started, I want to point that I'm not an expert in the topics I'm about to discuss. My goal was simply to see what some of my options were and to play around with some of them. I am sharing what I've found so far in the hopes that this helps some of you discover new things. More so, I hope this sparks a discussion with some of you who are further along in parallel computing than I am. Please feel free to correct me where I made errors or bad assumptions; I won't get offended, I promise.
The demo code I wrote for this post is available on GitHub. This probably isn't the best demo, but this was the best I could do to keep it concise for a blog post.
The .NET concurrency models I'll be discussing today are some of the data parallelism options offered by the TPL, such as Parallel.ForEach and Partitioner. I'll then be looking at the newly added SIMD (Single Instruction Multiple Data) capabilities to the .NET Framework. Finally, I'll touch on CUDA programming via the Alea package. I will not be discussing APIs that are meant for I/O intensive work, such as async/await.
Again, before starting, please understand that I am not an expert in any of the topics that I am about to discuss, and that besides some of the TPL offerings (which I've used plenty of times in the past), I've never played with this stuff beyond this blog post. In other words...

The Demo Program
The sample code we will be looking at is extremely simple. It's job is to take a very large array of integers and double all of the numbers inside of it. The single threaded function that accomplishes this is:
for (int i = 0; i < ARRAY_SIZE; i++)
{
array[i] = array[i] * 2;
}
This will serve as the baseline in all of our benchmarks. All tests are run in release mode.
The PC used for these tests uses an i7, 8-core (16 logical cores) CPU (5960x), with 64GB of DDR4 RAM, and an Nvidia GeForce GTX 960 with 2GB of GDDR5 RAM. My test run results will be different from yours.
Parallel.ForEach and Partitioner
I figured I'd start with something I knew fairly well, multithreading via the TPL. The TPL offers an easy to use extension method on IEnumerable (ForEach) that abstracts some of the ugly parts of parallel programming in .NET. If also offers things like ramp up of thread creation and other niceties out of the box.
Now, we could simply call ForEach() on the array, as seen below,
Snippet
Parallel.ForEach(array, i => array[i] = i*2);
but we'd probably get sub-optimal results because the operation is very simple, so most of the time will likely be spent on overhead. The TPL offers a Partitioner class that creates "chunks" of data for us to use. Those chunks can be distributed to other cores, and within the cores we can run tight loops.
Snippet
var partitioner = Partitioner.Create(0, ARRAY_SIZE);
Parallel.ForEach(partitioner.GetPartitions(Environment.ProcessorCount), p =>
{
while (p.MoveNext())
{
for (int i = p.Current.Item1; i < p.Current.Item2; i++)
{
array[i] = array[i]* 2;
}
}
});
To be honest, the operation here is so simple that even with this approach the overhead may be to high. Let's test it out.
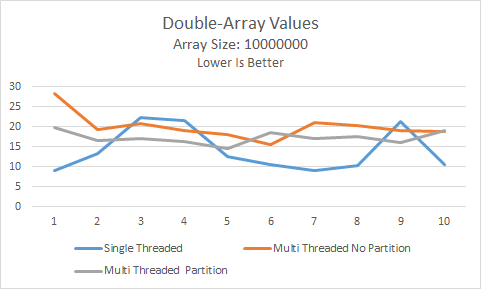
Over the course of 10 runs, the partitioned multi-threaded approach performed a little better than the non-partitioned version, but the overhead of both caused them to perform worse than the single-threaded version. Bummer.
This does demonstrate though that we should always benchmark; never assume going parallel == going faster!
SIMD - Single Instruction Multiple Data
Next up we try out the SIMD capabilities introduced with RyuJIT in the latest .NET Framework 4.6. SIMD instructions allow parallelism on a single CPU core.
To use the SIMD capabilities, I used the Vector class that come with the System.Numerics.Vectors namespace, pulled down via Nuget.
int vCount = Vector<int>.Count;
for (int i = 0; i < ARRAY_SIZE; i+=vCount)
{
var lhs = new Vector<int>(array, i);
Vector.Multiply(lhs, 2).CopyTo(array, i);
}
The .NET team made the Vector API backwards compatible with hardware that does not support SIMD, though you should probably check if SIMD is supported via the IsHardwareAccelerated property on Vector because your code will likely perform worse that the naive approach you would have used without SIMD.
Snippet
Vector.IsHardwareAccelerated
Note that the capabilities are hardware dependent. On my machine the width of Vector is 128 bits; that is, it can support support 16 bytes at once, 4 ints (or other 32 bit data structures), or 2 longs. You can find out by looking at the Vector<>.Count property.
On my machine, vCount was 4. The code simply loaded up vectors 4 ints at a time and multiplied all 4 in one operation. Think of it as going up the stairs 4 stairs at a time.

On my machine this was yielding results between 2x and 4x faster than the single threaded test. Now we're getting somewhere!
Remember though, that this was only on one core. Let's try combining SIMD with multi threading!
int vCount = Vector<int>.Count;
var partitioner = Partitioner.Create(0, ARRAY_SIZE);
Parallel.ForEach(partitioner.GetPartitions(Environment.ProcessorCount), p =>
{
while (p.MoveNext())
{
for (int i = p.Current.Item1; i < p.Current.Item2; i += vCount)
{
var lhs = new Vector<int>(array, i);
Vector.Multiply(lhs, 2).CopyTo(array, i);
}
}
});
And now let's crunch some numbers:
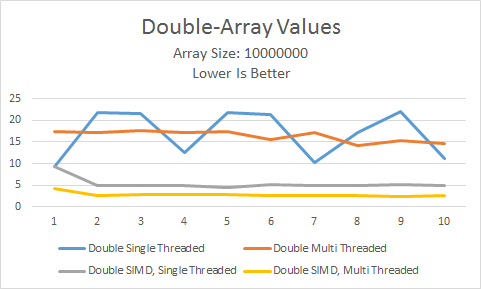
Hey now! A little worse than twice as fast as SIMD on a single core. Feels like we've got a winner here.

I'll be honest though, I don't understand why in this test SIMD on multiple cores outperforms single core SIMD consistently, as opposed to multiple threads vs single thread (non SIMD). I'm assuming in this case I'm just filling the lanes much more efficiently. I will look into it further, though I'd love to hear what someone that works with SIMD more often has to say about it.
CUDA
Now I'll be going way outside my comfort zone; but that's OK, we're learning, right?
Before I get started, I want to say that I expect this test to run significantly slower than the others. While the GPU can do lots of things in parallel, this test is very simple, and I think the overhead of getting the data to the GPU will be too great to overcome.
CUDA is an API invented by Nvidia and compete's with OpenCL, which is pushed by AMD.
There are libraries out there that support both CUDA and OpenCL, like Cudify.NET; though I will not be using that library because it required me to install the CUDA Toolkit, which I was unwilling to do, and would make running the examples more annoying to any reader that wants to play along.
The library I'll be using is Alea, which is CUDA only. Those without an Nvidia card will probably not be able to run these examples (sorry). I chose Alea because it did not require an install of any software. Alea can be obtained via a Nuget package. It also requires Fody. Note that if you're using Visual Studio 2015 or later, you should download the v3.0.2 version of Fody from Nuget, or you'll get random build errors (as in sometimes it works, sometimes it doesn't) and it will ruin your night.
Let's look at this simplistic example:
Gpu.Default.For(0, ARRAY_SIZE, i => array[i] = i*2);
Pretty cool, right? Not complicated at all. But how does this example run?
On the first run..... terrible; 1.5 seconds. On all of the subsequent runs the performance was much better, on the order of 12 or 13ms. I think we're seeing cache come into play here. Digging deeper, I modified the code to generate random array values on each cycle, and the benchmark results are the same, 1st run slow, subsequent runs fast. There's no way this could be any type of cache because the inputs are different every run. A google search yielded this, which I think explains what is happening under the hood.
There are a couple of possible explanations, but the most significant slowdown on the first kernel invocation comes from the need to just-in-time-compile PTX code to SASS instructions if no code four your GPU architecture is present. Make sure you include binary code for your architecture on compilation.
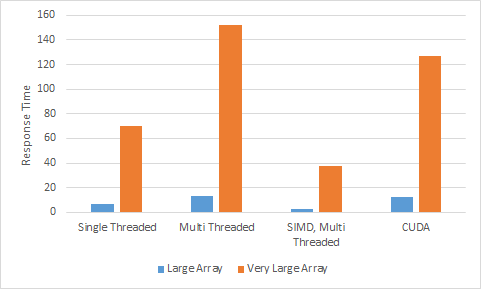
Final Test Results
For this simple demo, SIMD on multiple cores took the lead, followed by SIMD on a single core (not shown below). (I think) the overhead of thread management and coordination made the multi threaded solution slower than single core. Likewise, CUDA in this case was less efficient than just running on a single core (I'd appreciate other explanations if I got this wrong).
What Did We Learn?
At a minimum, we learned of the existence of .NET libraries that help you better utilize your hardware. We learned that not all models are great for all use cases. And of course we learned that we need to continuously test our assumptions when parallelizing code. My short term goals are to bone up a little on SIMD and GPU programming. I think I also want to dive deeper into the TPL, as I feel that I never use it beyond basic functionality in my day to day work.